YOLOv12を自分のデータでファインチューニングする手順を初心者向けに解説。学習コマンド、epochs/batch/imgsz/lr0などの意味、results.pngやPR曲線・混同行列の見方、best.ptをJetsonでTensorRT化して動作確認する流れまでまとめました。
この記事でできるようになること
- YOLOv12を自分のデータで学習(ファインチューニング)できる
- 学習後に出るグラフ(results.png / PR曲線 / 混同行列)の見方がわかる
- できた
best.ptを JetsonでTensorRT化して動作確認できる
1. そもそも「ファインチューニング」って何?
一言でいうと、すでに学習済みのYOLOモデル(例:yolo12n.pt)を土台にして、自分のデータに合わせて追加学習することです。
- 0から作る(最初から全部学習) → 時間もデータもたくさん必要
- ファインチューニング → 少ない手間で精度が出やすい(現場ではこれが基本)
今回のコマンドはまさに「ファインチューニング」です。
2. 準備:データ(data.yaml)ができていればOK
すでに data.yaml が用意できている前提で進めます。
例:
path: dataset_c
train: images/train
val: images/val
names:
0: cucumber
1: cut3. 学習コマンド(基本形)
まずは一番ベーシックな形。
yolo detect train model=yolo12n.pt data="dataset_c\data.yaml" epochs=100 imgsz=640 batch=16 device=0 name=agri_yolo_trainそれぞれの意味(難しい言葉なし版)
model=yolo12n.pt:学習の“土台”になるモデル(nは軽いモデル)data=...yaml:自分のデータの場所とクラス名epochs=100:学習を何周するか(多すぎても良くならないことがある)imgsz=640:学習時の画像サイズ(大きいほど細かい物に強いが重い)batch=16:一度にまとめて学習する枚数(大きいほど速くなりやすいがメモリを使う)device=0:GPUを使う(0番のGPU)name=...:結果フォルダ名
4. 個人的にお薦めコマンド(高速化・安定化込み)
例:
yolo detect train model=yolo12n.pt data="dataset_c\data.yaml" epochs=200 imgsz=960 batch=64 device=0 name=agri_y12n_960 lr0=0.001 close_mosaic=20 cache=ram workers=8 amp=Trueここで追加したものを、簡単に説明します。
lr0=0.001(学習の“進み方”の強さ)
- 大きいほど変化が大きい(良くも悪くも動く)
- 小さいほどじっくり(安定しやすい)
目安:まずは 0.001 は良いスタートです。
close_mosaic=20(学習の後半は“合成”をやめて丁寧に学習)
YOLOは学習中に画像を混ぜるような“強めの加工”をします(mosaic)。close_mosaic=20 は、最後の20エポックはその加工をやめて、実画像に近い状態で仕上げるイメージです。
→ 仕上げ精度が良くなりやすいです。
cache=ram(画像をメモリに置いて読み込みを速くする)
- メリット:学習が速くなる
- デメリット:PCのメモリ(RAM)をたくさん使う/環境によって落ちることがある。安定しないなら使用するのやめる。使わなくても精度に影響はない。
workers=8(読み込み係を増やす)
- メリット:読み込みが速くなる → 学習も速くなることが多い
- デメリット:Windowsやメモリ不足環境だと落ちやすいことがある。こちらも安定しないなら使用するのやめる。使わなくても精度に影響はない。
amp=True(半分の精度で計算して高速化)
- 多くの場合、速度が上がってメモリも節約できます
- 精度が大きく落ちることは通常少ない(現場でよく使われます)
5. 「学習が遅い」時に効く順番(RTX3090想定)
私の環境だと batch=32 が早かったです。GPUのスペックが低い場合は16や8などにして試す感じです。
おすすめの順番はこれです:
- batchを上げる(VRAMが許す範囲で)
cache=ramを試す(落ちるならやめる)workersを上げる(落ちるなら下げる)amp=Trueを使う
batchが大きいと何が嬉しい?
ざっくり言うと、GPUを遊ばせずに働かせられるので速くなりやすいです。
ただし 大きすぎるとメモリ不足で落ちるので、VRAMと相談です。
6. 学習が途中で落ちるとき(よくある原因と対策)
私が遭遇したようなエラーは、だいたい「読み込み(DataLoader)とメモリ」の問題です。
対策(上から順に試す)
workersを下げる(例:8 → 4 → 2 → 0)cache=ramをやめる(cache=Falseかcache=disk)batchを少し下げる- それでもダメなら
imgszを下げる(960→768→640)
例(安定寄り):
yolo detect train model=yolo12n.pt data="dataset_c\data.yaml" epochs=200 imgsz=960 batch=32 device=0 name=agri_y12n_960_stable lr0=0.001 close_mosaic=20 cache=False workers=2 amp=True7. 学習が終わったらどのモデルを使う?(best.ptとlast.pt)
学習後にだいたいこの2つが出ます。
best.pt:いちばん成績が良かった瞬間のモデル(基本これを使う)last.pt:最後のエポックのモデル
✅ 実運用はまず best.pt でOKです。
8. 結果の見方(ここが一番大事)
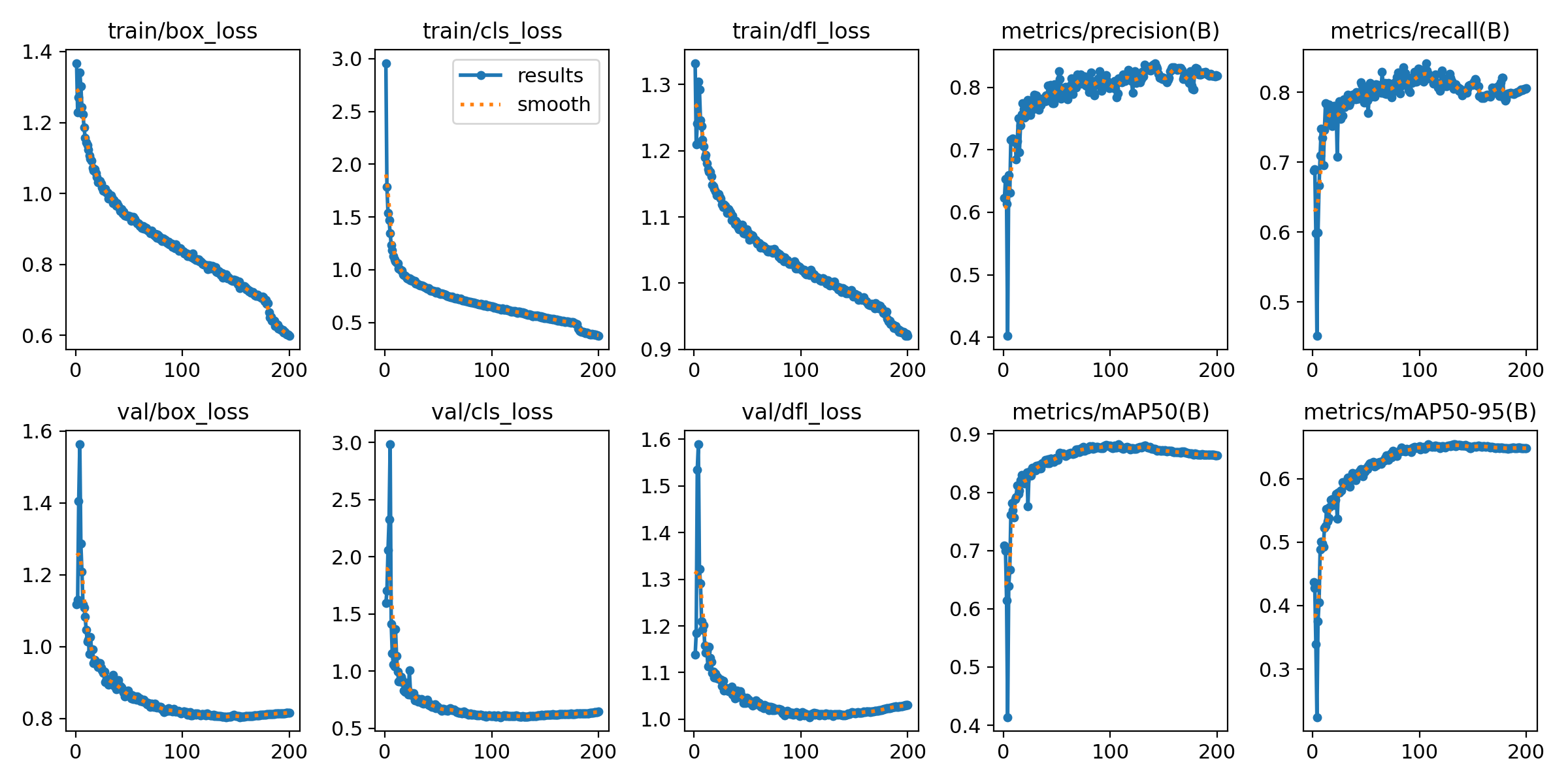
8-1. results.png(学習の推移グラフ)
見るポイントは2つだけでOKです。

train/*loss(学習中のミスの量)
→ 下がっていけばOKmetrics/mAP50とmetrics/mAP50-95(成績)
→ 上がっていけばOK、途中から横ばいなら「頭打ち」
あなたのグラフは、mAPが早めに伸びて、その後はゆっくり(または横ばい)なので、
「200以上回せば大きく伸びる」というより、データ改善や調整のフェーズに入っています。
8-2. PR曲線(Precision-Recall)

- 線が右上に張り付くほど良い
cucumberよりcutが下なら、cutの方が難しい(よくある)
👉 精度を上げたいなら、エポック追加よりも
cutの画像パターンを増やす / ラベルのブレを減らすが効きます。
8-3. F1-Confidence曲線(confを決めるヒント)
このグラフは「conf(検出の厳しさ)をどこに置くとバランスが良いか」の目安になります。

- F1が最大になるconf付近 → まずそこを推論confの初期値にする
例:all classes のピークが 0.49 なら
- まず
conf=0.5で試す - 誤検出が多ければ
0.6〜0.7 - 取り逃しが嫌なら
0.3〜0.4
8-4. 混同行列(confusion_matrix)


ここは超シンプルに見ます。
- 本当は背景なのに、cucumber/cutと判定している数が多い
→ 誤検出が多い
この誤検出を減らす最短手はこれです:
✅ 「何も写ってない画像(ラベル空)」を学習に入れる
(背景を背景として覚えられるので、誤検出が減りやすい)
9. 「キュウリとcutの枚数を同じにするためにキュウリを減らすべき?」
基本は 減らさない方が良いです。
理由:キュウリ側の“見た目のバリエーション”が減って、かえって弱くなることがあります。
やるならこうします:
- cut画像を増やす(撮影追加 or アノテ追加)
- cutが難しい条件(暗い・逆光・小さい・ブレ)を増やす
- ラベルの置き方が人によってブレてないか確認(cutは特にブレやすい)
10. best.ptをJetsonでTensorRT化して確認する流れ
重要:TensorRTの変換はJetson上でやるのが一番安全です(環境依存が強いので)。
おすすめの流れ(失敗しにくい)
- 学習PCで
best.ptを用意 - Jetsonに
best.ptをコピー - Jetson上で TensorRT化(engine作成)
- Jetson上で推論して速度と検出を確認
まとめ
誤検出が多いなら 背景画像(ラベル空)追加が強い
YOLOv12の学習は model= yolo12n.pt を指定すればファインチューニング
results.png で「頭打ち」なら、エポック追加より データ改善が効く
できた best.pt は JetsonでTensorRT化して使うのが安全
次の記事ではここで作成したモデルをjetsonで動かす方法を紹介していきたいと思います。
それではまた。






LEAVE A REPLY